成為大型語言模型開發者要面對的事
引爆你的大型語言模型開發之旅:掌握提示語、LLM和LangChain 優勢
TL;DR
本文主要介紹成為大型語言模型開發者所需面對的挑戰,包括使用提示與與大型語言模型對話、各種開源語言模型介紹,以及開發工具 LangChain 。此外,文章也談到大型語言模型的應用、各家版本和開源模型 Alpaca。
由 Glarity Summary 插件製作文章摘要

前言
在數位時代的浪潮中,大型語言模型的開發正成為一個引人注目的領域。對於初次接觸大型語言模型開發者來說,了解提示、Prompt、LLM和LangChain等常見名詞,將是你踏上這個令人興奮的旅程的關鍵。
在本篇文章中,我們將探索成為一名成功的大型語言模型開發者所需面對的挑戰和事項。我們將從最基礎的概念開始,解釋提示是如何引導大型語言模型生成相關和適當的輸出。進一步介紹Prompt的應用,以及如何運用LLM和LangChain等開發工具來實現更精準和可控的輸出。
本文旨在為初學者提供一個全面且易於理解的入門指南,同時也對經驗豐富的開發者提供了寶貴的洞察和策略。無論你是尋找靈感還是希望提升你的開發技能,這篇文章都將為你提供實用的資訊和寶貴的建議!
目錄
- 提示語 — Prompt
- 大型語言模型 — Large Language Model
- 開發工具 — Development Kit
提示語 — Prompt

介紹
提示語一種對大型語言模型輸入的方式,以便能夠生成相關和適當的輸出。提示語是一種文本輸入形式,其包含問題陳述、文本描述、對話等不同形式。當模型接受到提示語輸入時,會基於該上下文所提供的語義信息,產生對應的輸出文本。
使用場景
目前最泛用的應用就是透過 ChatGPT 來理解,還沒有玩過的話,可以在瀏覽器上輸入 ai.com 直接體驗一把跟語言模型互動的魅力,可以做到以下事情。
撰寫標題

撰寫行銷文案

使用模式
截至今日,人們已經發展出多種常見的溝通方式,使得語言模型能夠更加裡人們所要表達的含義。
方式ㄧ、zero-shot prompt
在 Zero-shot prompt 中,我們可以讓語言模型透過既有的知識直接回答問題,不管是分類、總結、問題發想等都可以。
請幫我判斷以下句子是屬於喜怒哀樂哪一種情緒?
問題:翠果,打爛他的嘴!
回答:方式二、Few-shot prompt
透過 Few-shot prompt 可以用作一種支援上下文學習的技術,我們在提示中提供演示以引導模型獲得更好的性能。直白點就是給出幾個小範例,可以讓語言模式更加理解我們的含義
請根據以下顏色與形容詞的關係,針對問題回答
1. 綠色代表新生
2. 藍色代表寒冷
3. 紅色代表熱情
請問黃色可以代表什麼?方式三、Role Playing
角色扮演是容易理解的環節,可以請語言模型以一名面試官的身份來對學生進行模擬面試等。
請你扮演一家餐飲公司的線上客服,當有顧客反應說菜色的品質有問題時,我們有什麼具體的步驟可以處理?更多閱讀材料
上面資訊算是精簡版本,我在下方列出可以查看更多資訊的地方。
大型語言模型 — Large Language Model;LLM

介紹
在我們日常生活中,人工智能已經變得越來越無所不在,而大型語言模型就是其中一種最具影響力的人工智能技術。那麼,什麼是大型語言模型呢?
大型語言模型是一種機器學習系統,它可以生成與其訓練數據相似的文字。這種模型通過學習大量的文本資料,理解語言的模式和規則,然後用這些知識生成新的、合乎語境的文本。你可以把它想象成一個巨大的、能夠生成各種文本的機器。
大型語言模型的應用範疇非常廣泛。例如,它們可以被用來撰寫文章、回答問題、翻譯語言,甚至可以創作詩歌或故事。它們也被用在許多我們日常生活中的產品和服務中,例如語音助手(比如 Siri 或 Alexa)、聊天機器人,以及一些高級的搜索引擎。
各家版本 LLM
目前各家所使用的大型語言模型主要由 OpenAI 開發的 GPT4 為主軸,Meta 也有提供模型 Llama 給開發人員使用,但不小心被洩露,目前在開源軟體上多以該模型往下研發,最大宗即為 Alapca,由 Standford 團隊所製作的。
從此開啟大羊駝時代,各種基於 Alpaca 方法實作的小模型,並配合常見的 PEFT 策略製作出屬於各領域的專家 Domain,後來多到學者建立擂台讓這些模型互毆,藉此判斷哪家模型強,可參考 Chatbot Arena

復課窮人版本羊駝
這個環節我覺得李宏毅老師講的很齊全了,建議要做這事的同仁,可以先閱讀個幾遍。
摘要
本期講解如何在有限資源下自己復刻ChatGPT,並介紹相關資安問題與OpenAI對資料使用的回應。
重點
- 🤖 分享三個大型語言模型的最新故事
- 📚 窮人如何用有限資源復刻自己的ChatGPT
- 🔒 資安問題和OpenAI對資料使用的回應
- ❌ 如何刪除使用者資料的方式
- 📄 使用現成的pre-trained模型和ChatGPT的API
- 🎓 以ChatGPT為師的複刻方法
- 🧠 學習問題的輸入與讓ChatGPT幫忙想例子
影片連結
經驗分享
說是窮人版本,但其實要消耗的資源也是滿多的,假設你只有一張 2080Ti 訓練總共 70k 的 Instruction 資料,走過 3 個 epoch,大概需要 200 小時。不然還有雲端方案,可以到 GCP 租借 A100 來玩玩。
開發工具 — Development Kit

LLM 固然強大,但如何導入 Prompt 讓使用者每次對話都是角色,如何使用開源 LLM 模型建置為應用程式後端,管理輸出的格式,不讓語言模型回答出帶有歧視、傷害性的回答,這些都是工程的面向,這邊你需要熟練掌握 LangChain 這樣的工具,並且將向量文本放入向量資料庫中。
LangChain
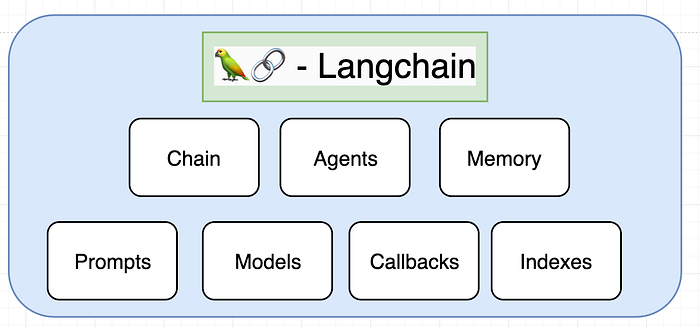
LangChain 是一套基於語言模型開發用的框架,主要帶三種角色,Agent、Data-aware、Interface,提供大型語言模型對外聯絡的管道,跟既有的服務串接 API,如 Zaiper,跟現有資料庫索取資料,如 MongoDB,或是分析文檔,如 PDF,都行。
LangChain 主要職責為替語言模型這顆大腦裝上手腳耳朵,具有對外的能力,當中提供六個模組,Prompt、LLM、Index、Chain、Agent、Memory 進行操作。
以下示範如何透過 LangChain 實作 CSVGPT,透過自然語言方式跟既有CSV對話,自動轉換語意並且透過 tool 執行 python 編譯等操作,這邊我們使用寶可夢 CSV 做為練習。
from langchain.llms import OpenAI
## 建構
agent = create_csv_agent(OpenAI(temperature=0), '/content/gdrive/My Drive/pokemon.csv', verbose=True)
## 詢問問題
agent.run("What is Pikachu stats?")> Entering new AgentExecutor chain...
Thought: I need to find Pikachu's stats in the dataframe.
Action: python_repl_ast
Action Input: df[df['Name'] == 'Pikachu']
Observation: # Name Type 1 Type 2 Total HP Attack Defense Sp. Atk \
30 25 Pikachu Electric NaN 320 35 55 40 50
Sp. Def Speed Generation Legendary
30 50 90 1 False
Thought: I now know the final answer
Final Answer: Pikachu has a total stat of 320, HP of 35, Attack of 55, Defense of 40, Sp. Atk of 50, Sp. Def of 50, and Speed of 90.
> Finished chain.
Pikachu has a total stat of 320, HP of 35, Attack of 55, Defense of 40, Sp. Atk of 50, Sp. Def of 50, and Speed of 90.透過上面的案例中,可以體驗到 Langchain 來搭建屬於自己的語言模型應用程式是可控的,Langchain 當中還有其他方式來達成效果,並且客製化屬於自己專案上需要的功能。
Llama index
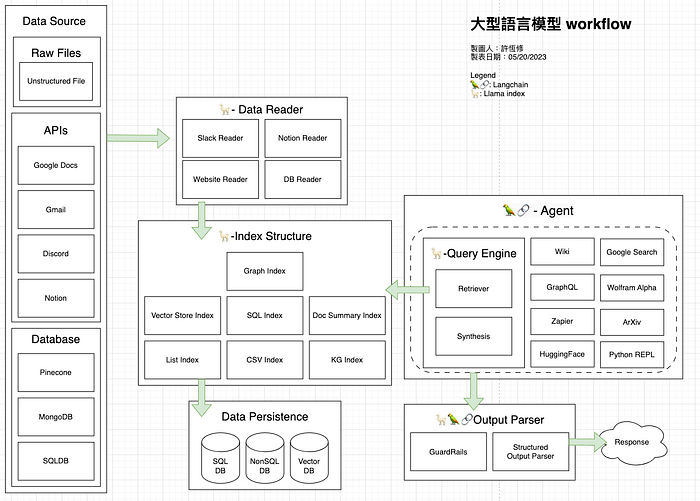
Llama index 專注在解決處理文檔資料結構,以及查詢文本資料的功能上,為此強化,當中提供 Index Structure 作為文檔資料結構,常見的資料結構都有,如 List, Tree, Graph, Knowledge Graph, 以及 Compose Graph ,可以藉此提供跨文檔搜尋功能。
以下示範如何整合 LLama index 與 Langchain 進行互動,可以參考這份專案
## 使用 List 方式建構 Index
list_index = GPTListIndex.from_documents(city_docs)
## 將 LLama-index 作為 Langchain 當中 Tool 使用
tools = [
Tool(
name = "GPT List Index",
func=lambda q: str(list_index.as_query_engine().query(q)),
description="useful for when you want to answer questions about Taiwan. The input to this tool should be a complete Traditional Chinese sentence. And the output also does.",
return_direct=True
),
]
## 呼叫 LangChain 當中 Agent 回答問題
agent_executor = initialize_agent(tools, ChatOpenAI(temperature=0), agent="conversational-react-description")
agent_executor.run(input="請介紹台北歷史文化,並且使用正體中文回答")'台北歷史悠久,文化豐富。從台灣發展初期開始,台北就扮演了重要的角色。一些著名的歷史文化地標包括國立故宮博物院,收藏了大量的中國藝術和文物,以及中正紀念堂,紀念中華民國的前總統蔣介石。台北其他受歡迎的景點還包括台北101摩天大樓、龍山寺和士林夜市。'後話
剛開始接觸到 LangChain 以及 Llama-index 時,會覺得兩者做的事情很像,甚至裡頭有許多函數命名近乎一樣,例如兩者都有 Retriever、VectoreStore 等。把視角拉高點可以知道,其實 Llama-index 專注提供狀態管理機制。
工商時間
如果你需要知道更多資訊,可以參考我在 Udemy 平台上的 Langchain 課程,是裡面目前第一個中文授課的 Langchain 內容,點擊以下連結可以直接享受優惠代碼
