CRAG: 革命性AI技術如何讓機器回答更精準?
探索Corrective RAG(CRAG)如何通過創新的檢索評估和知識精練機制,大幅提升AI問答系統的準確性和可靠性。本文深入剖析CRAG的工作原理,並與傳統RAG和Self-RAG進行對比,揭示其在AI領域的革命性潛力。

1. 什麼是 CRAG?
Corrective RAG(糾錯檢索增強生成),主要提高語言模型生成穩健性的方法。此法中通過評估器和網路檢索針對檢索到到文檔相關性,進行番評估與增加,以確保說在生成回應中保有更為精準、可靠的訊息。
1.1 開書考試的各種策略
想像你正在參加難得的開書考,面對考卷上的試題,你可能會有以下幾種作答策略:
- 方法一、開書考沒用,直接憑記憶上
對於熟悉的題目,直接憑藉記憶快速作答。而對於不熟悉的題目,則查閱參考書,找到相關章節,快速理解並總結,然後將答案寫在試卷上。 - 方法二、考卷是天書,每題都查找
對於每一道題目,都仔細查閱參考書,找到相關章節,理解並總結內容,然後將答案寫在試卷上。 - 方法三、前晚有惡補,不會的再找
快速回答熟悉的題目。對於不熟悉的題目,可以參考參考書,快速找到相關章節,並在頭腦中進行整理和歸納,然後將答案寫在試卷上。 - 方法四、書上寫的跟考卷一樣嗎?
對於每一道題目,都查閱參考書並找到相關章節。在形成答案之前,你會將收集到的信息進行分類,區分哪些是正確的、哪些是錯誤的,哪些是模稜兩可的。然後,你會分別處理每種類型的信息,最終將整理和總結後的答案寫在試卷上。
這四種策略分別對應了三種不同的信息檢索和答案生成方式。第一種策略類似於人類憑藉自身知識儲備直接作答。第二種策略類似於傳統的檢索增強生成 (RAG) 技術。第三種策略類似於 Self-RAG 技術。第四種策略則對應著本文將要介紹的 糾正性 RAG 模型 (CRAG)。
1.2 傳統RAG的困境: 為什麼AI有時會”胡說八道”?
傳統的檢索增強生成(RAG)技術雖然強大,但也面臨著兩大挑戰:
- 資訊相關性低: 就像一個學生在考試時胡亂翻書,卻沒有找到真正有用的內容。
- 資訊雜亂無章: 想像一下,如果你的參考書是一本雜亂無章的大雜燴,你能找到準確的答案嗎?
這些問題導致AI有時會生成看似合理,實則錯誤的”幻覺”內容。
1.3 CRAG 提出 傳統 RAG 中可以改善空間
鑑於檢索增強生成,在檢索資訊過程中存在些局限性,可能會導致後續生成內容的真實性以及品質。以下是作者整理出的局限性重點,並且用圖表表達之。

問題一、檢索資訊的相關性過低
傳統的 RAG 方法往往沒有充分考慮檢索到的文件與問題之間的相關性,而是將所有檢索到的文件簡單地合併在一起,作為生成模型的輸入。這會導致大量無關信息的引入,進而影響生成模型對知識的理解,並可能導致模型生成與事實不符的“幻覺”內容。
問題二、資訊過於雜亂,不夠精準
傳統的 RAG 方法通常將整個檢索到的文件作為輸入,但實際上,文件中的大部分內容可能與生成的內容無關。這些冗餘信息不僅會增加模型的計算負擔,還會影響模型對關鍵資訊的提取和利用。
1.3. CRAG 提出什麼機制解決問題?
CRAG 提出傳統 RAG 會有檢索資訊品質不夠好問題,導致生成答案錯誤。為此 CRAG 作者群提出 Retrieval Evaluator(檢索評估器) 以及 Knowledge Refinement(知識精練) 兩個機制來解決上述問題。以下是兩者的運作機制:
Retrieval Evaluator(檢索評估器):
用於評估針對特定問題檢索到的文件的整體品質。它還會利用網路搜索作為輔助工具,進一步提升檢索結果的品質。
評估答案分為「正確」(correct)、「模糊」(Ambiguous)、「錯誤」(Incorrect)三種情況。對於「正確」的情況,直接進行知識精練,抽取關鍵資訊。針對「錯誤」的資訊,則利用網路檢索來擴充知識量。針對「模糊」的知識,結合前面兩種操作來提供答案的穩健性及精準度。
Knowledge Refinement(知識精練):
先將文件進行分解再重新組合,以便深入挖掘文件中的核心知識點。
利用自訂規則將文件進行分解,並由檢索評估器來衡量其相關性。最後將剩餘的相關知識重新整合。
1.3.1 在 CRAG 中Retrieval Evaluator做了啥?
檢索評估器可以被視為一個評分分類模型。該模型用於確定查詢與文件之間的相關性,類似於 RAG 中的重新排序(re-ranking)模型。
這種相關性判斷模型可以通過整合更多符合現實世界場景的特徵來進行改進。例如,科學論文問答中的 RAG 包含許多專業術語,而旅遊領域的 RAG 則往往包含更多口語化的用戶查詢。
CRAG 使用一個輕量級的 T5-large 模型作為檢索評估器,並對其進行了微調。值得一提的是,即使在大語言模型的時代,T5-large 模型仍然被認為是輕量級的。
對於每個輸入的問題,CRAG 通常會檢索十個相關的文件。然後,系統會將問題與每個文件分別組合在一起,作為輸入數據,讓 T5-large 模型預測它們之間的相關性。在微調過程中,模型會將標籤 1 分配給正樣本(與問題相關的文件),將標籤 -1 分配給負樣本(與問題無關的文件)。在推理過程中,評估器會為每個文件分配一個介於 -1 到 1 之間的相關性分數。
1.3.2 在 CRAG 中Knowledge Refinement做了啥?
CRAG 設計了一種新穎的知識提取方法,即先將文檔分解再重新組合,以便深入挖掘文檔中的核心知識點。
首先,利用一系列規則將文檔細分為較小的知識單元,目的是獲取更精細的知識點。如果檢索到的文檔僅包含一句或兩句話,則將其視為一個整體。如果文檔較長,則根據其總長度進一步細分為包含數個句子的小單元,每個單元都應包含一個完整的信息點。
然後,利用檢索評估器為每個知識單元計算相關性評分,篩除那些評分較低的單元。剩下的、評分較高的知識單元將被重新組合,構建成完整的內部知識體系。
1.4 實作
LangChain 通過 LangGraph 來實現 CRAG,您可以參考下圖來理解。不過,該實現對 CRAG 進行了一些簡化和調整(當然,您也可以根據需求進行定制和擴展):
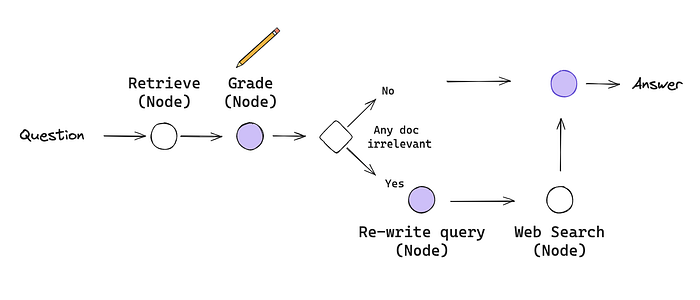
- 作為第一道工序,跳過知識提煉階段。雖然知識提煉是一種有趣且有價值的後處理形式,但對於理解如何在 LangGraph 中布局這一工作流程並不是必須的。
- 如果所有文件都與查詢不相關,則通過網路搜尋進行補充檢索。這裡將使用 Tavily Search API 來進行網路搜尋,它既快速又方便。
- 使用查詢重寫(re-write query)來優化網路搜尋的查詢。
- 在進行分支決策時,使用 Pydantic 對輸出進行建模,並將該函數作為 OpenAI 工具提供,每次 LLM 運行時都會調用該函數。這樣,我們就能為條件邊的輸出進行建模,因為在這種情況下,分支邏輯的一致性至關重要。
這個實現也是體現 RAG 流程工程(flow engineering)的例子,包括特定的決策點(如文件分級)和迴圈(如重試檢索)。
程式碼:https://colab.research.google.com/drive/1z1eZYZJJQj4-t98Ck3zMhqAxDaF1ZkVl#scrollTo=7l9dgGfC9e4q
1.5 CRAG 與 Self-RAG 比較
- 工作流程:self-RAG 可以直接使用大型語言模型生成答案,無需進行信息檢索。而 CRAG 則需要先檢索相關信息,然後進行評估和篩選,最後才生成答案。
- 模型結構:self-RAG 的模型結構比 CRAG 更複雜,需要進行更複雜的訓練過程,並在生成答案時進行多標籤生成和評估。這導致 self-RAG 的推理成本更高,效率更低。而 CRAG 的模型結構較為輕量級,推理速度更快。
- 性能表現:根據表1所示的實驗結果,CRAG 在大多數情況下都優於 self-RAG,能夠生成更準確、更相關的答案。

總的來說,CRAG 和 self-RAG 各有優缺點。self-RAG 更適合那些對信息檢索速度要求較高,但對答案準確性要求不太高的場景。而 CRAG 則更適合那些對答案準確性要求較高,但對信息檢索速度要求不那麼高的場景。
參考資料
1. 論文連結:https://arxiv.org/abs/2401.15884
